Details
-
Improvement
-
Resolution: Unresolved
-
 Major
Major
-
1.1.11, 1.2.3, 1.3.0-alpha5
-
None
-
AWS m5.xlarge ec2 instance, vCPU num: 4
Description
Our log servers deployed logback component, the logback configuration contains tens of appenders, this is one of the appender definition:
<appender name="rawdata"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/data/xxx/rawdata/rawdata.log</file>
<encoder>
<pattern>%m%n</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/data/xxx/rawdata/rawdata.log.%d{yyyy-MM-dd-HH}.gz</fileNamePattern>
</rollingPolicy>
</appender>
please note the "fileNamePattern" value, we use gzip compression, it means in each hour beginning, all the tens of files are renamed to tmp files, then be compressed in the thread pool. Currently, this thread pool core size is immutable, a fixed value: 8, which came from https://github.com/qos-ch/logback/commit/b946551439134
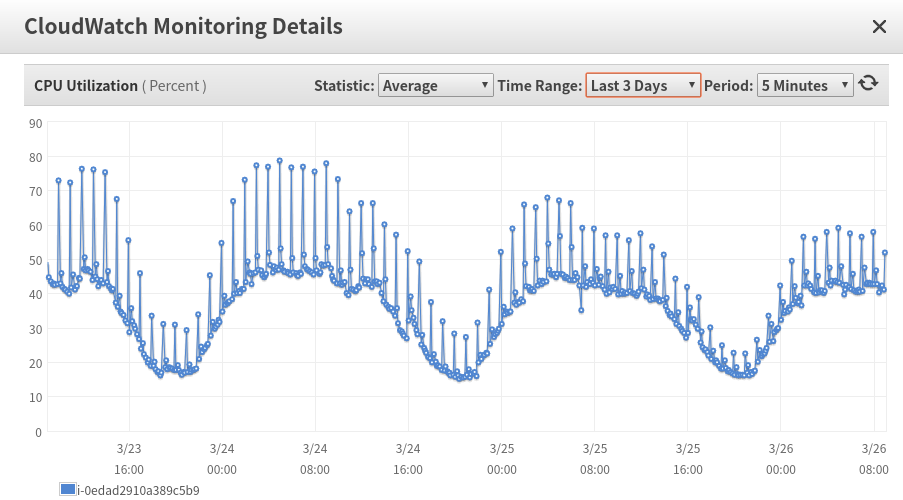
In an small ec2 env with tens of big log files(a few of our rolling raw log files size are 10 Gb), say 4 vcore, the compression will be last several minutes with all vcores running in full speed.
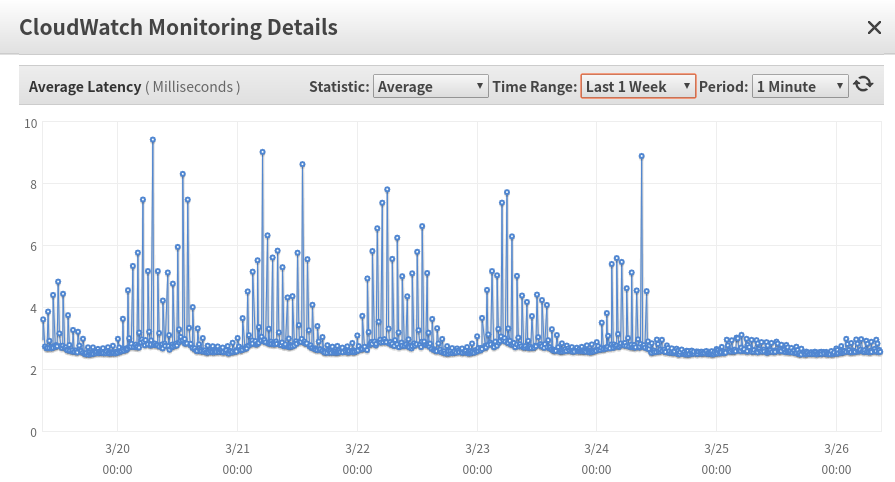
It will disturb the normal user request latency espencially under a high throughput env.
Our proposed solution are as following:
1. let SCHEDULED_EXECUTOR_POOL_SIZE be configurable, it is meaningful since the logback users have different cpu core configs, different requirements(latency vs throughput)
2. let the compression level be configurable, currently, the logback uses JDK's GZIPOutputStream class, which deflate algorithm is DEFAULT_COMPRESSION always. It would be great if we could make it be configurable.
We forked a branch, after updating SCHEDULED_EXECUTOR_POOL_SIZE to 1 and deflate algorithm to BEST_SPEED, we have observed the each hour beginning's cpu spikes were relieved , and the user request latency is more stable than before
Any comments are welcome
Attachments
{kind=link}
{kind=link}
Issue Links
- relates to (in)
-
-
- Open
-